Note: This document has not been updated with information on the convolution method
Introduction
This document provides details about the different performance aspects of the package. There are two general issues users should be aware of: computation time and memory (RAM) usage.
Computation time is the more straightforward of the two. Basically, as the size of the landscape data increases, the amount of time it takes the calculations to run will also increase. Additionally, many functions have a time parameter for calculating short-term metrics. As the time parameter increases, users should expect a proportional increase in computation time (with an important caveat discussed below). A recommended strategy for users is to initially use low resolution version of their landscape data and low time inputs for initially writing and verifying their scripts. This allows users to incrementally test things until they are satisfied everything is working correctly without needing to wait long periods of time for testing. Then, once ready, they can start using their final inputs, or even first incrementally increasing the size of the data and time parameters as a way to gauge how long their final analysis will take to complete.
The more complex issue is RAM usage. All of the calculations involve matrix calculations that can consume large amounts of memory. In some cases, the calculations can be optimized to avoid the more memory intensive calculations, but in other cases it is unavoidable, and will limit how some functions in the package can be used. It is important for users to be aware of the limitations of each function they wish to use. Failing to do so may result in excessive RAM utilization. In some cases, the analysis may still run by using the hard drive as additional RAM, but this will slow the analysis by one to three orders of magnitude, and can cause disk wear that is particularly detrimental to solid state drives (SSDs). Otherwise, the analysis will likely crash R, potentially causing loss of work. Writing the initial analysis using a scaled down versions of the user’s landscape data, and then later incrementally increasing the resolution is one approach for determining what is possible to run on a user’s system.
Transition Matrix
All of the calculations performed by the package make use of a transition matrix generated using the landscape data. Technically, the size of the transition matrix grows quadratically with the number of cells in the landscape data, meaning that it can quickly consume a computer’s available memory (RAM). The following figure illustrates this, where even a million landscape cells (a 1000x1000 raster without any missing data) requires ~7500 GB of RAM, about 1000x what is typically available in modern consumer computers.
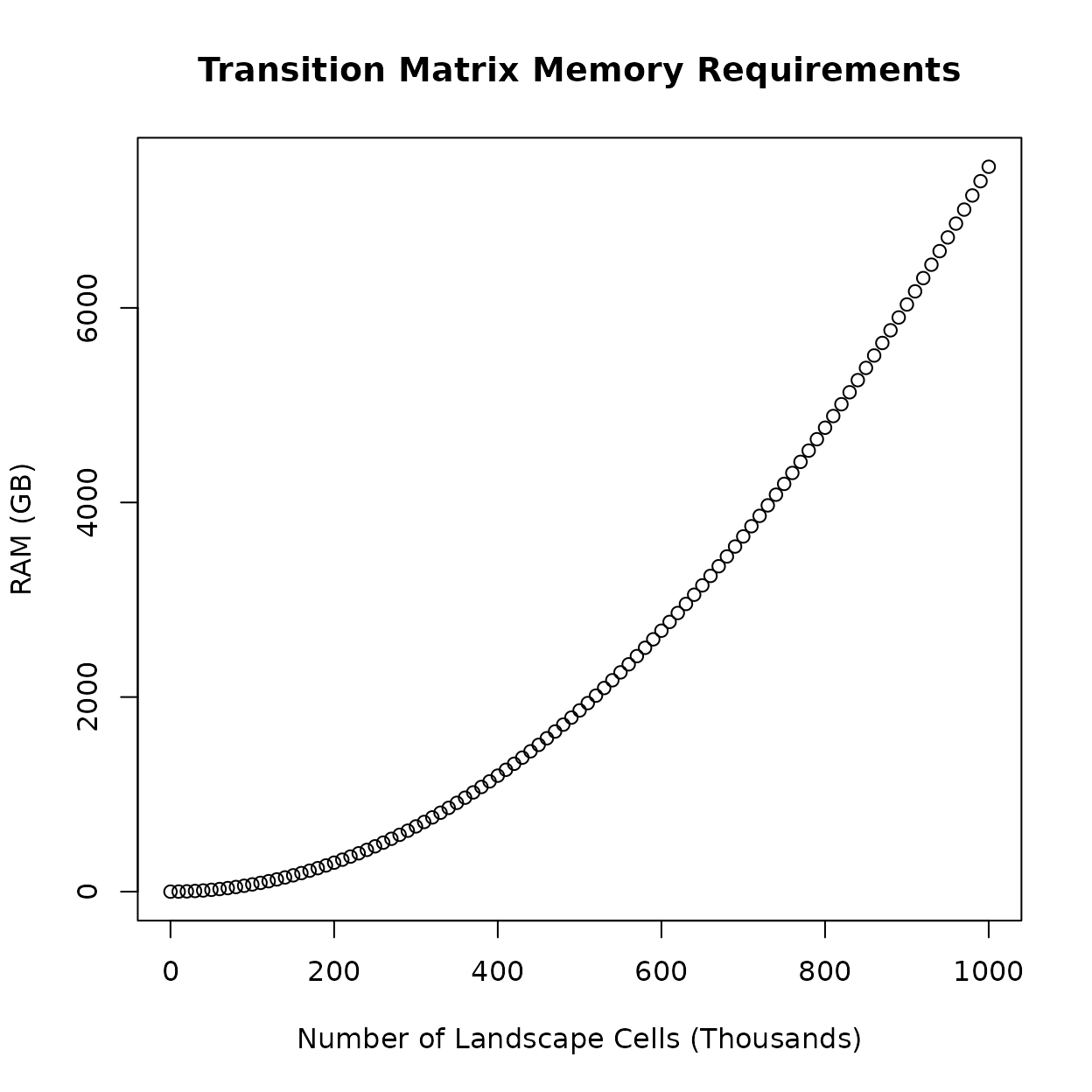
Fortunately, the initial transition matrix is sparse (it contains the
value 0 in the majority of its cells). This allows the way
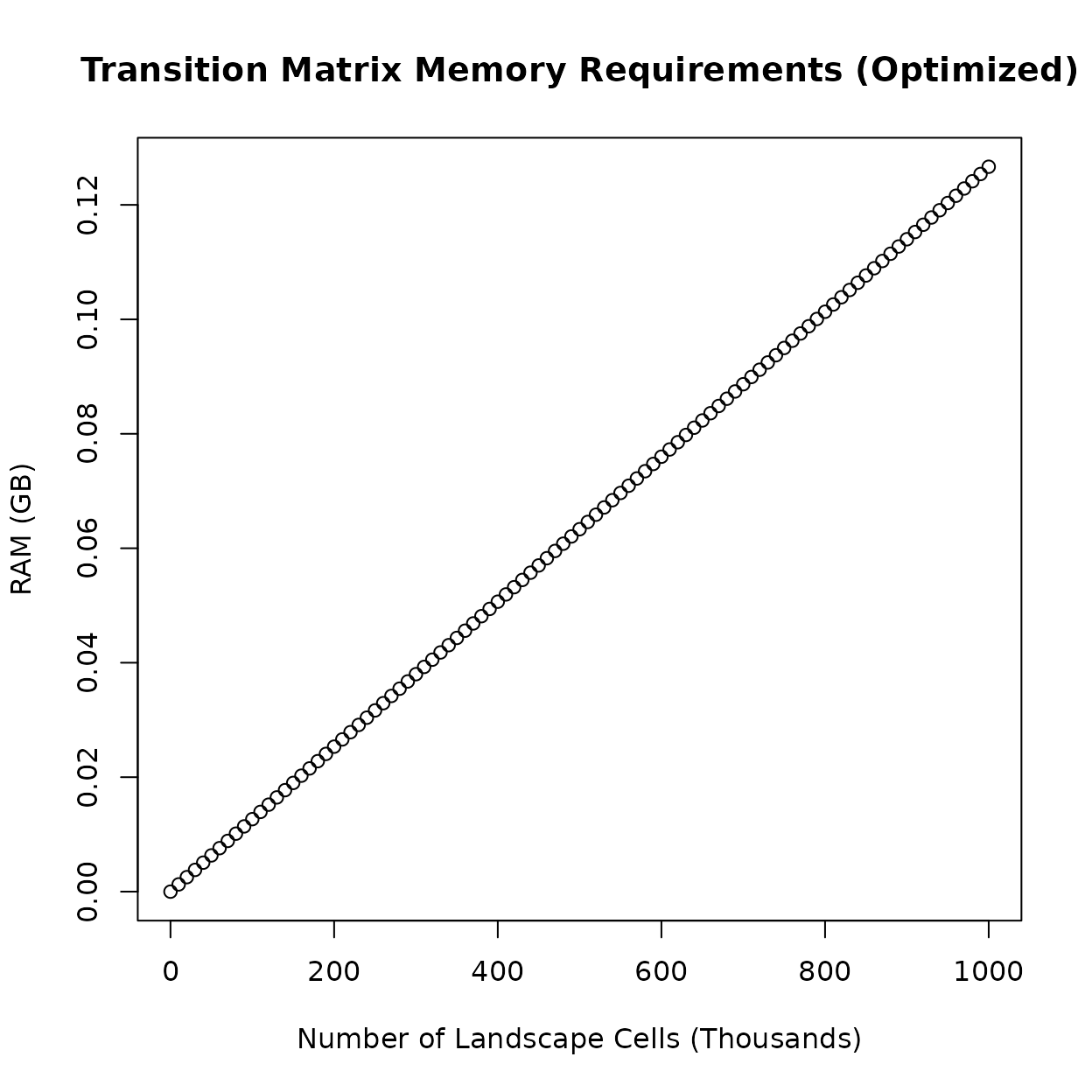
it is stored in RAM to be optimized so that the amount of memory it
consumes only grows linearly with the number of cells in the landscape
data. In practice, this means the transition matrix takes up
significantly less RAM. Using a 1000x1000 landscape raster (one million
landscape cells) again as an example, the transition matrix can be
condensed down to less than 0.15 GB of RAM.
Calculations
Creating a large transition matrix is no longer the limiting factor in terms of memory, but issues still arise when the transition matrix is used in calculations. Some calculations involving the transition matrix, such as calculating the inverse, will produce a dense matrix that cannot be stored in a similarly optimized manner. Instead, the dense matrix will have the same memory requirement as the first figure above. These calculations quickly become impractical with even moderately-low amounts of landscape data. The following figure illustrates how many landscape cells could be practical with consumer hardware when these calculations are involved. This is under ideal circumstances; in practice, more than one dense matrix may need to be in memory at the same time to perform some calculations.
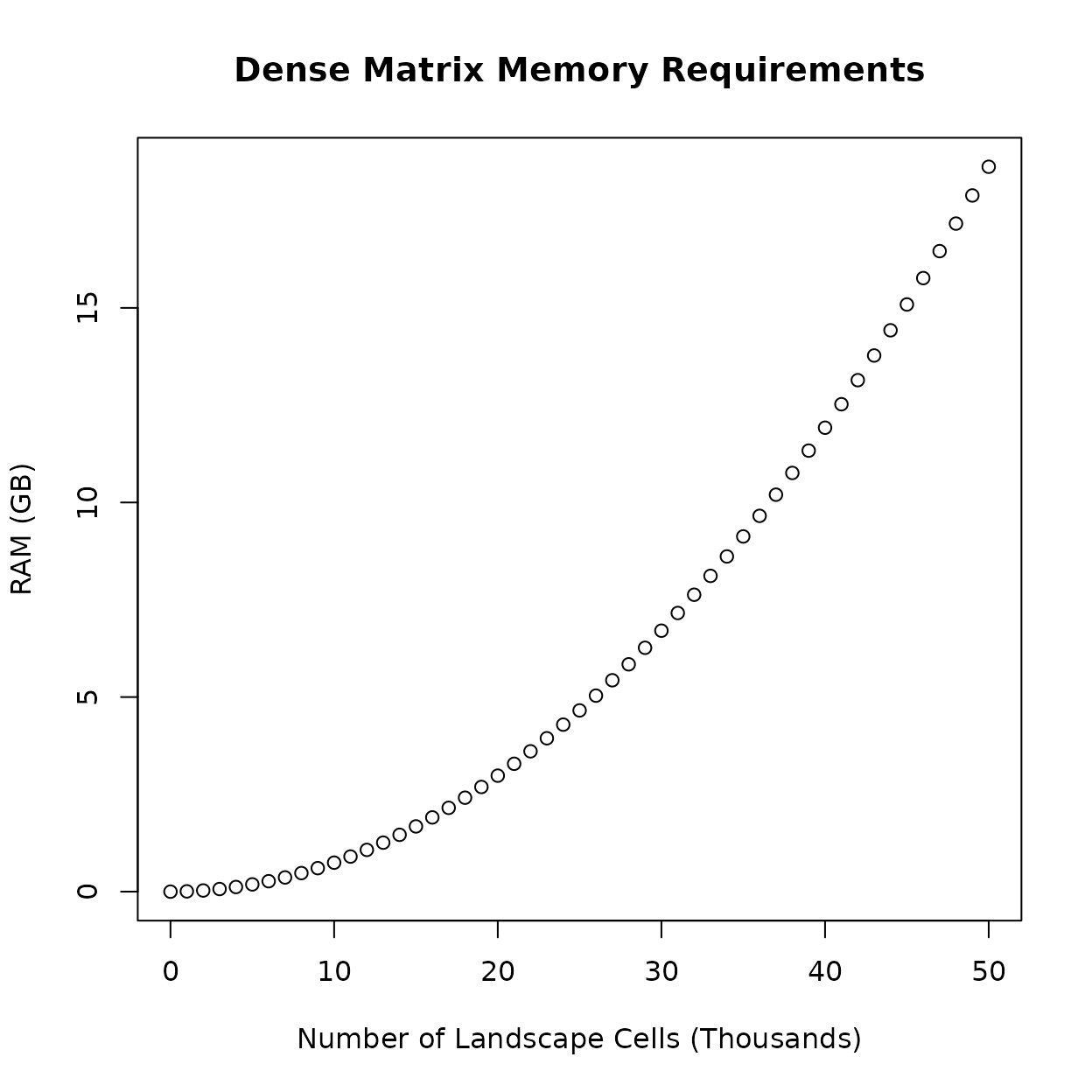
Many of the equations in the SAMC paper perform these calculations. In some cases it is completely unavoidable. Fortunately, in other cases, it is possible to refactor the equations to avoid these particular calculations, or to use other math techniques and tools that limits their downside.
Solvers
There are many different algorithms for solving systems of linear equations on computers. The most straightforward are direct solvers, which use a sequence of operations to deliver an exact solution (not accounting for rounding limitations of hardware). Iterative solvers generate a sequence of improving approximate solutions until some criteria is met (e.g., max time, max number of iterations, min tolerance, etc). In the case of transition matrices generated from raster data, direct solvers appear to generally be significantly faster, but they require a large amount of memory in the process. In contrast, iterative solvers appear to be slower in general (depending on the structure of the data, they might be faster in rare situations), but are substantially more memory efficient.
Prior to version 3.0.0, the samc package always used a direct solver.
As of version 3.0.0, the direct solver is still used by default, but now
samc-class objects can now be switched between the direct
solver and an iterative solver. In general, the direct solver should be
used where possible, and the iterative solver should be used when the
problem cannot be solved within the memory constraints of the system.
The iterative solver in samc runs until the error of the result is
within the tolerance of the machine precision; in other words the
iterative solver should have 15-16 digits of precision for most modern
computers, which is a limitation of the direct solver as well.
Not all metrics in samc depend on linear solvers; of the short-term
metrics, only dispersal() will be affected by the choice of
solver.
Short-term Metrics
The short-term metrics (functions where a number of time steps is specified) are expected to have a run time that increases linearly with the number of time steps (as seen in the benchmarks below). Currently, a limitation in the way numbers are stored in computer hardware is causing these calculations to slow down substantially with large time steps (~47000 on one test computer). Until a suitable workaround is identified, users are recommended to start their analyses with smaller numbers and increase them incrementally. Plotting these incremental results may reveal that a large number of time steps is not necessary in order for the results to stabilize for some/all short-term metrics.
Special Cases
dispersal(samc, origin) & dispersal(samc, init)
These metrics have been optimized for memory usage, but due to the requirement of calculating diag(F), remain substantially slower than solutions for metrics. Additionally, as the number of transient states increases, the time to compute the result increases quadratically. Once calculated, however, the result of diag(F) is cached and reused in future runs of these metrics. So only the first time running these metrics for a particular samc-class object will be slow.
Given how slow calculating diag(F) can be, progress updates are provided during different stages of the calculation. The first stage involves a matrix decomposition that generally will take less than a few minutes, but could take several minutes with large datasets. The second stage is by far the most time consuming part of the calculation, and a time estimate will be periodically updated to give users a rough estimate of how long it will take to complete. The first few time estimates tend to be inflated due to the low sampling time, but will improve with each update. During the calculation, other software running on the computer can affect how fast the calculation runs, and in turn, lead to changes in time predictions. Once diag(F) is calculated, obtaining the final result for these metrics will take an amount of time comparable to other metrics.
As of v1.5.0, these functions support parallel computing to reduce the time required for calculating diag(F). See the Parallel Computing vignette for details.
Benchmarks
This section includes automated benchmarks for each method that has been optimized to avoid memory issues. This information is primarily for prioritizing future optimizations, but is published in case some users find it helpful. The benchmarking approach is crude and there may be occasional outliers as a result. Computation time could vary quite a lot with different hardware.
Overall Performance
v3.0.0: needs to be updated
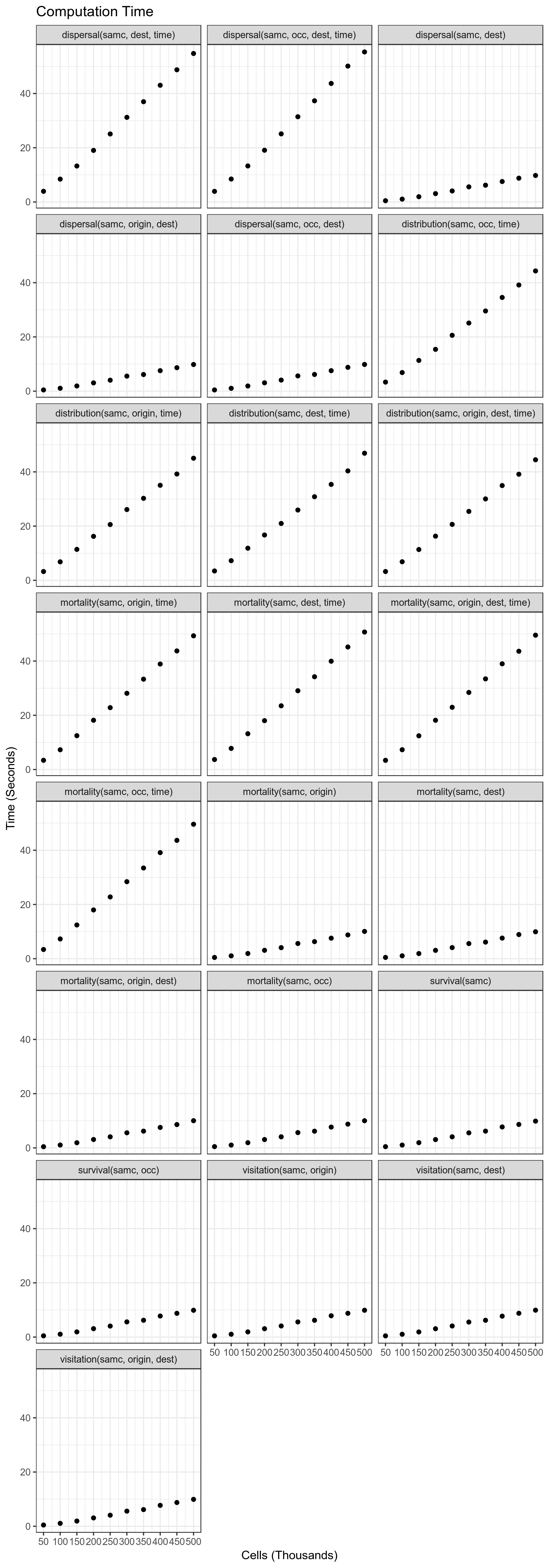
Performance of each of the functions relative to number of landscape
cells. For short-term metrics, the number of time steps was set to
10000.
Overall Memory Usage
Removed. The profiling tools in R do not measure the memory consumed by native code. In other words, the figures only showed the memory used by the R parts of the code, not the C++ parts, which caused the memory consumption figures to dramatically underestimate memory usage. An external tool has been identified and memory benchmarks will be redone in the future.
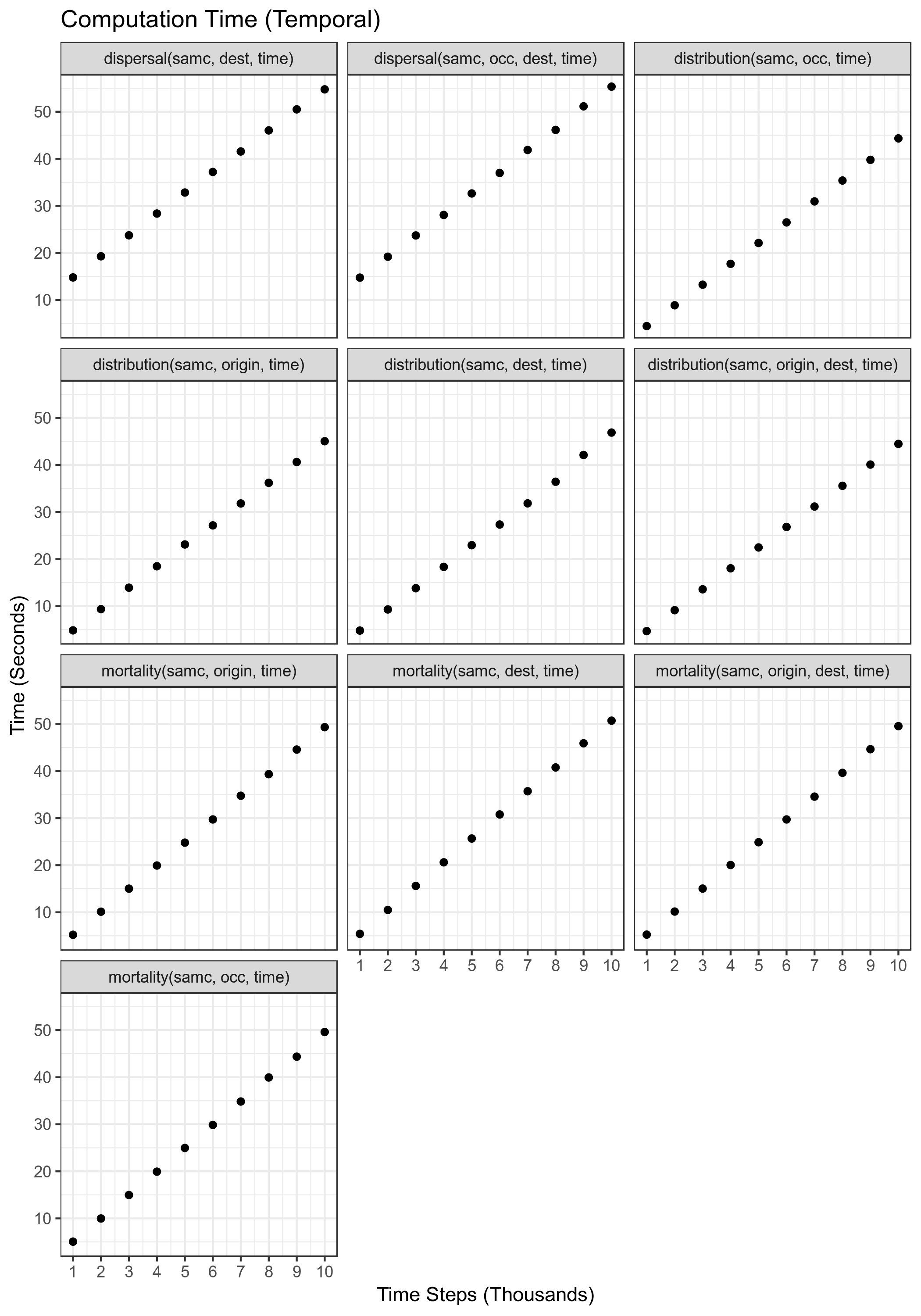
Temporal Performance
v3.0.0: needs to be updated
Performance of each of the short-term metrics for varying number of time steps. The number of landscape cells used for this benchmark was 500,000.
Temporal Memory Usage
Removed. The profiling tools in R do not measure the memory consumed by native code. In other words, the figures only showed the memory used by the R parts of the code, not the C++ parts, which caused the memory consumption figures to dramatically underestimate memory usage. An external tool has been identified and memory benchmarks will be redone in the future.